


Projects
Research in the Speech Disorders & Technology Lab (SDTL) is highly interdisciplinary with a focus on motor speech disorders and assistive speech technologies. Those topics are across several disciplines including speech science, motor speech disorders, neuroscience/neuroimaging, computer science, biomedical engineering and electrical and computer engineering. Specifically, the research topics in the lab are, but not limited to, below:
-
Assistive speech technologies including silent speech interface for laryngectomees, dysarthric speech recognition and analysis, speech synthesis
-
Neurogenic motor speech disorders due to and digital (speech) biomarkers for amyotrophic lateral sclerosis (ALS)
-
Neural speech decoding for brain-computer interfaces (BCIs)
Highlights
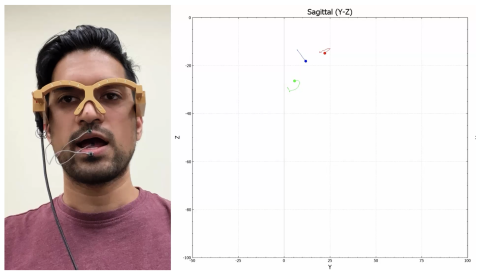
MagTrack: A wearable, magnetic tracking based silent speech interface
Current electromagnetic tongue tracking devices are not amenable for daily use and thus not suitable for silent speech interface and other applications. We have recently developed MagTrack, a novel wearable electromagnetic articulograph tongue tracking device. Our preliminary validation indicated MagTrack for potential silent speech interface applications (Cao et al., JSLHR 2023).
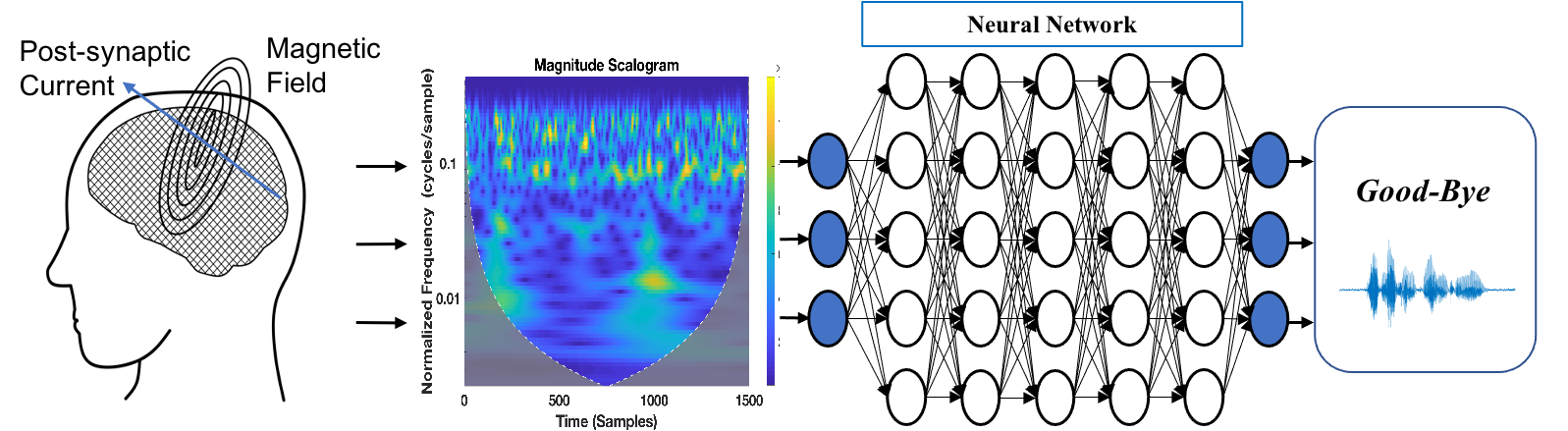
Decoding speech from Neural (MEG) Signals for Individuals with ALS
Direct decoding of speech production from neural signals has potential to enable a faster communication rate for patients who are in locked-in state (fully paralyzed, but aware) than current word spelling based brain-computer interfaces (BCIs). This project aims to decode imagined and spoken speech from non-invasive neural signals. Magnetoencephalography (MEG) uses highly sensitive magnetometers and gradiometers to record the magnetic fields associated with intracellular post-synaptic neuronal current transmission in the brain, which yields a higher spatial resolution than EEG and a higher temporal resolution than fMRI. We have recently demonstrated the possibility to decode a small set of imagined and spoken phrases from MEG signals with accuracy higher than 90% for healthy controls (Dash et al., Front. Neuosci. 2020) and up to 85% for individuals with ALS (Dash et al., Interspeech 2020).
Fingerprint in the Brain: Speaker identification from neuromagnetic signals
Brain activity signals are unique biological features for persons that can neither be stolen nor be forged, hence hold promising inferences for next-generation biometric identifiers. In this study, we investigated magnetoencephalography (MEG) signals for speaker identification using data obtain from eight speakers. MEG records the magnetic field induced by the postsynaptic current from the cortical surface neurons with a higher spatial resolution. Besides resting state, we also experimented on speaker classification from the brain activity signals during speech tasks. Speech is an inherent trait of the speakers, and hence may be more helpful for high performance identification. Results show the speaker identification was up to 100% using the data from the best two MEG sensors during speech tasks. Using the data in rest state, data from the best nine sensors are needed to reach 100% accuracy (Dash et al., Interspeech 2019).

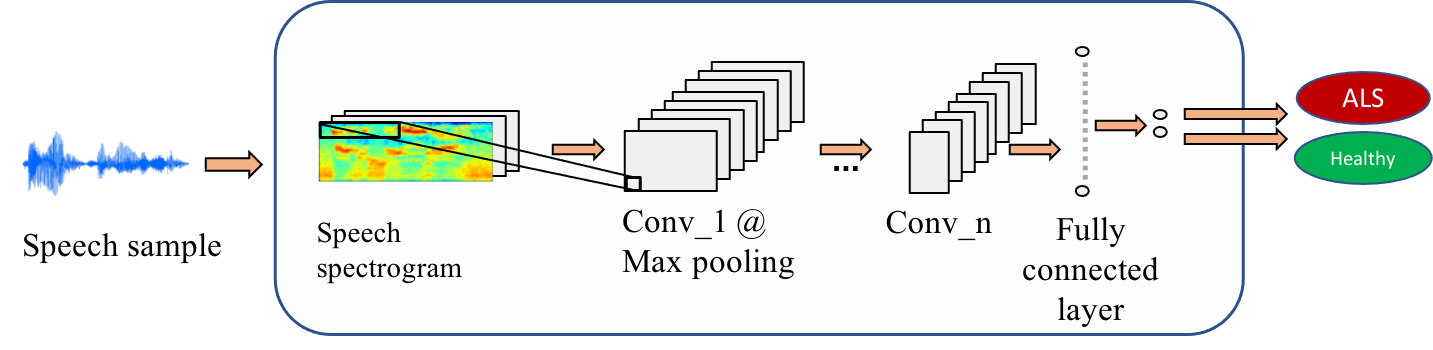
Automatic detection of early ALS from intelligible speech
There is no biomarker and thus no currently definite diagnostic procedure for ALS. The current diagnosis of ALS is provisional, based primarily on clinical observations of upper and lower motor neuron damage in the absence of other causes. Considering the rapid progression of ALS, ealry diagnosis is particulaly critial for ALS. This research aims to advance the early diagnosis of ALS using speech informationn (both acoustic and kenametic data) and machine learning. Preliminarey results indiated the approach is promosing (Wang et al. ,2016; An et al., 2018). This research is featured in a commentary article in Nature Outlook (Salvage, 2017).
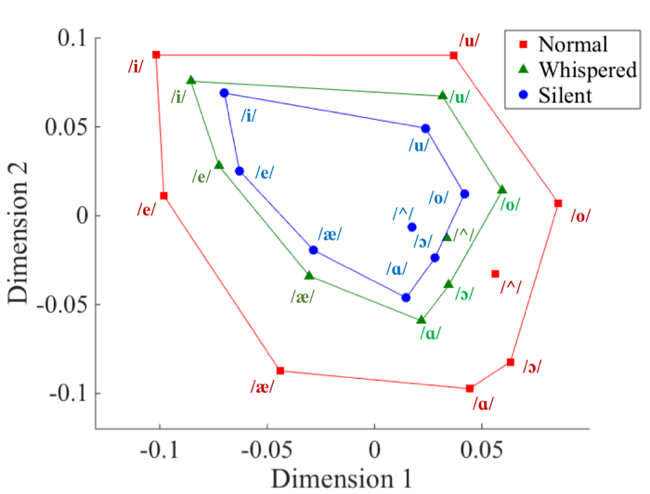
Articulatory Distinctiveness Space of Normal, Whispered, and Silent Vowels
To better understand the general articulatory distinctiveness of vowels in different speech conditions (normal, whispered, and silent), a novel, robust approach called articulatory vowel distinctiveness space (AVDS) was used to generate a space that is based on the general kinematic pattern difference (rather than direct tongue and lip displament/positions). See the AVDS below, where silent vowel space is smaller than whispered space, which is smaller than normal (voiced) space. This finding suggests silent and whispered vowel production are less distinct than voiced vowel production without vocal fold vibration (Teplansky et al., ICPhS 2019).
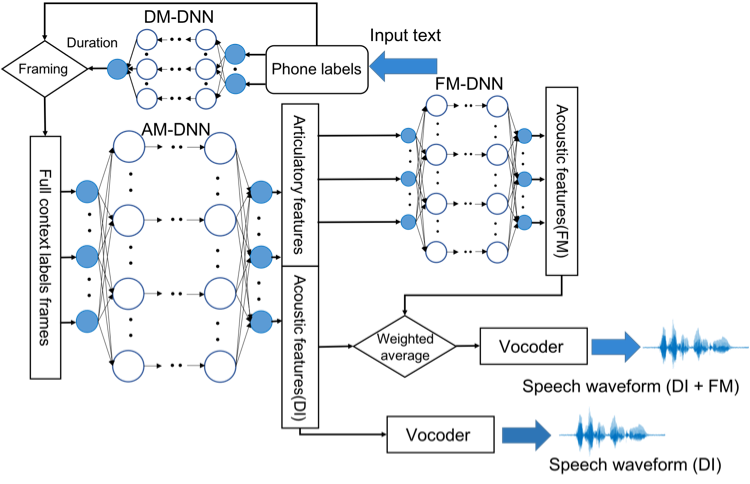
Integrating Articulatory Information in Deep-learning Text-to-Speech Synthesis
Articulatory information has been shown to be effective in improving the performance of hidden Markov model (HMM)-based text-to-speech (TTS) synthesis. Recently, deep learning-based TTS has been demonstrated outperforming HMM-based approaches. This works investigated integrating articulatory information in deep learning-based TTS. The integration of articulatory information was achieved in two ways: (1) direct integration, and (2) direct integration plus a forward-mapping network, where the output articulatory features were mapped to acoustic features by an additional DNN. Experimental results show adding articulatory information significantly improved the performance (Picture adapted from Cao et al., 2017).
DJ and his Friend: A Demo of Conversation Using the Real-Time Silent Speech Interface
This demo shows how the silent speech interface is used in a daily conversation. DJ (the user) is using the silent speech interface to communicate with his friend (not shown on the screen). DJ is mouthing (i.e., without producing any voice) and the silent speech interface displays the text on the screen, and produces synthesized sounds (female voice) (Wang et al., SLPAT 2014).
Demo of Algorithm for Word Recognition from Continuous Articulatory Movements
In the demo below, the top panel plots the input (x, y, and z coordinates of sensors attached on the tongue and lips); the bottom panel shows the predicted sounds (time in red) and actual sounds (time in blue). This algorithm conducts segmentation (detection of onsets and offsets of the words) and recognition simultaneously from the continuous tongue and lip movements (Wang et al., Interspeech 2012; SLPAT 2013).
Demo of Algorithm for Sentence Recognition from Continuous Articulatory Movements
In the demo below, the top panel plots the input (x, y, and z coordinates of sensors attached on the tongue and lips); the bottom panel shows the predicted sounds (time in red) and actual sounds (time in blue). This algorithm conducts segmentation (detection of onsets and offsets of the sentences) and recognition simultaneously from the continuous tongue and lip movements (Wang et al., ICASSP 2012).
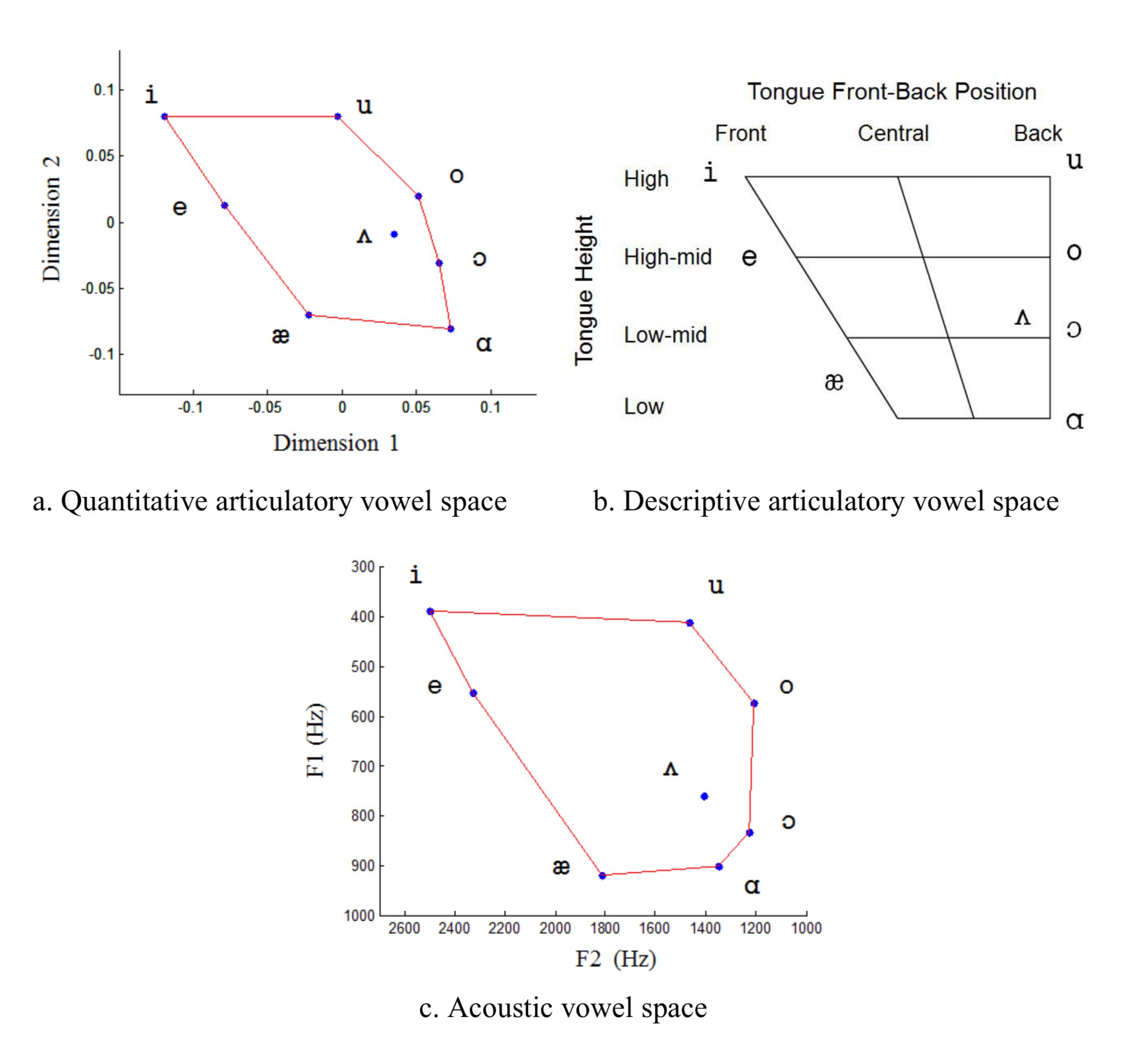
Quantitative Articulatory Vowel Space
The left part of the graphic is the quantitative articulatory vowel space I derived from more than 1,500 vowel samples of tongue and lip movements collected from ten speakers, which resembles the long-standing descriptive articulatory vowel space (right part). I’m now investigating the scientific and clinical applications of the quantitative articulatory vowel space (Wang et al., Interspeech 2011; JSLHR 2013).
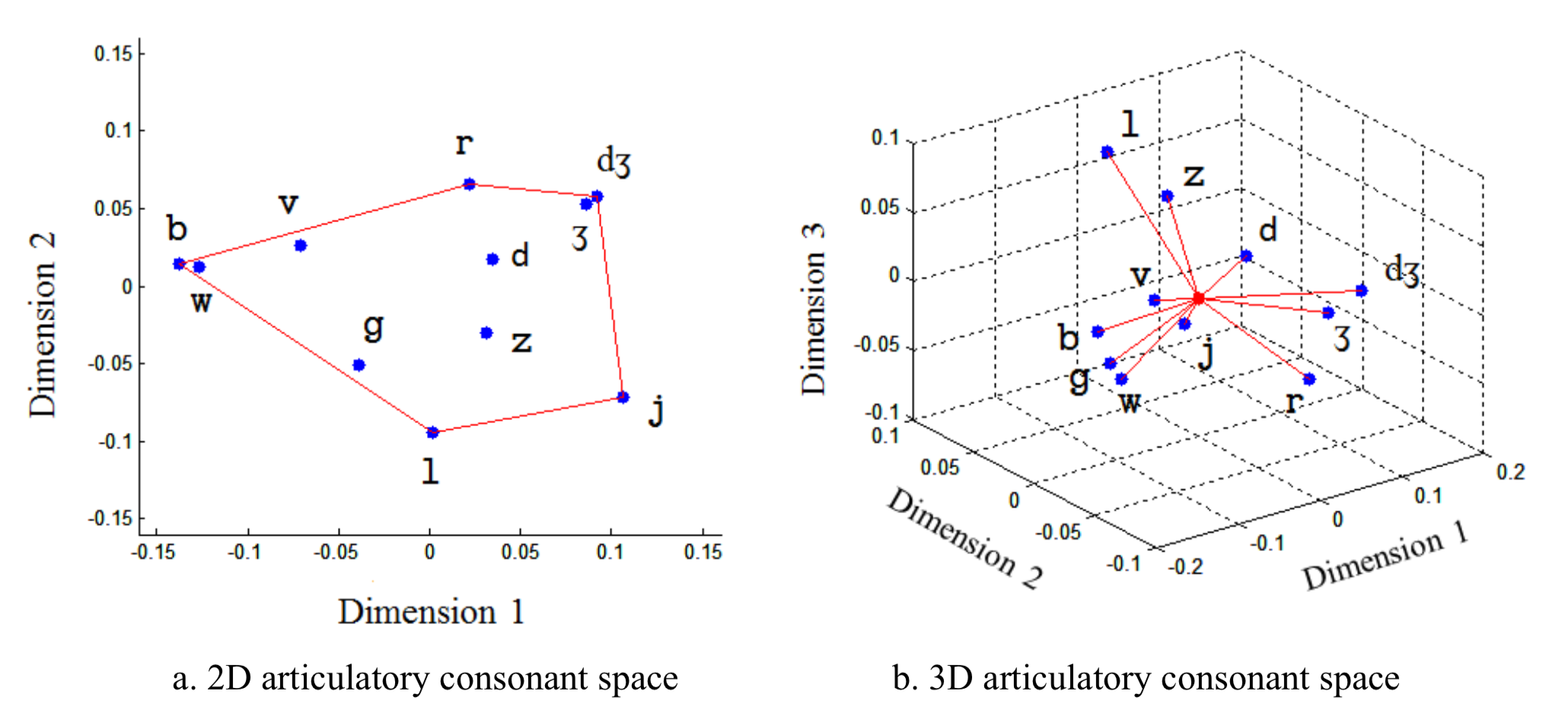
Articulatory Consonant Space
Using the same approach, articulatory consonant spaces were derived using about 2,100 consonant samples of tongue and lip movements collected from ten speakers. See the figure below (2D on the left and 3D on the right). Both consonant spaces are consistent with the descriptive articulatory features that distinguish consonants (particularly place of articulation). Another interesting finding is a third dimension is not necessary for the articulatory vowel space, but very useful for consonant space. I’m now investigating the scientific and clinical applications of the articulatory consonant space as well (Wang et al., JSLHR 2013).
Speech Motor Control of Amyotrophic Lateral Sclerosis (ALS)
This is a collaborative project with MGH, U of Toronto, and UT Dallas, where where SDTL focuses on the articulatory sub-system of ALS bulbar system (Green et al., ALSFD 2013; see a test protocol video on the Journal of Visualized Experiments).
